cardinality 
determinants
multiple-fact, multiple-grain queries
Before you begin, there are concepts that you need to understand.
Relational modeling concepts:
cardinality
determinants
multiple-fact, multiple-grain queries
Model design considerations:
relationships and determinants
minimized SQL
metadata caching
query subjects vs. dimensions
shortcuts vs. copies of query subjects
folders vs. namespaces
Dimensional modeling concepts:
regular dimensions
measure dimensions
scope relationships
When modeling in Framework Manager, it is important to understand that there is no requirement to design your data source to be a perfect star schema. Snowflaked and other forms of normalized schemas are equally acceptable as long as your data source is optimized to deliver the performance you require for your application. In general, we recommend that you create a logical model that conforms to star schema concepts. This is a requirement for Analysis Studio and has also proved to be an effective way to organize data for your users.
When beginning to develop your application with a complex data source, it is recommended that you create a simplified view that represents how your users view the business and that is designed using the guidelines in this document to deliver predictable queries and results. A well-built relational model acts as the foundation of your application and provides you with a solid starting point if you choose to take advantage of dimensional capabilities in Cognos 8.
If you are starting with a star schema data source, less effort is required to model because the concepts employed in creating a star schema lend themselves well to building applications for query and analysis. The guidelines in this document will assist you in designing a model that will meet the needs of your application.
Relationships exist between two query subjects. The cardinality of a relationship is the number of related rows for each of the two query subjects. The rows are related by the expression of the relationship; this expression usually refers to the primary and foreign keys of the underlying table.
Cognos 8 uses the cardinality of a relationship in the following ways:
to avoid double-counting fact data
to support loop joins that are common in star schema models
to optimize access to the underlying data source system
to identify query subjects that behave as facts or dimensions
A query that uses multiple facts from different underlying tables is split into separate queries for each underlying fact table. Each single fact query refers to its respective fact table as well as to the dimensional tables related to that fact table. Another query is used to merge these individual queries into one result set. This latter operation is generally referred to as a stitched query. You know that you have a stitched query when you see coalesce and a full outer join.
A stitched query also allows Cognos 8 to properly relate
data at different levels of granularity .
Framework Manager supports both minimum-maximum cardinality and optional cardinality.
In 0:1, 0 is the minimum cardinality, 1 is the maximum cardinality.
In 1:n , 1 is the minimum cardinality, n is the maximum cardinality.
A relationship with cardinality specified as 1:1 to 1:n is commonly referred to as 1 to n when focusing on the maximum cardinalities.
A minimum cardinality of 0 indicates that the relationship is optional. You specify a minimum cardinality of 0 if you want the query to retain the information on the other side of the relationship in the absence of a match. For example, a relationship between customer and actual sales may be specified as 1:1 to 0:n. This indicates that reports will show the requested customer information even though there may not be any sales data present.
Therefore a 1 to n relationship can also be specified as 0:1 to 0:n, 0:1 to 1:n, or 1:1 to 0:n.
Use the Relationship impact statement in the Relationship Definition dialog box to help you understand cardinality. For example, Sales Staff (1:1) is joined to Orders (0:n).

It is important to ensure that the cardinality is correctly captured in the model because it determines the detection of fact query subjects and it is used to avoid double-counting factual data.
When generating queries, Cognos 8 follows these basic rules to apply cardinality:
Cardinality is applied in the context of a query.
1:n cardinality implies fact data on the n side and implies dimension data on the 1 side.
A query subject may behave as a fact query subject or as a dimensional query subject, depending on the relationships that are required to answer a particular query.
Use the Model Advisor to see an assessment of the behavior implied by cardinality in your model.
For more information, see Single Fact Query and Multiple-fact, Multiple-grain Query on Conformed Dimensions.
The role of cardinality in the context of a query is
important because cardinality is used to determine when and where
to split the query when generating multiple-fact queries. If dimensions
and facts are incorrectly identified, stitched queries can be created
unnecessarily, which is costly to performance, or the queries can
be incorrectly formed, which can give incorrect results .
The following examples show how cardinality is interpreted by Cognos 8.
In this example, Sales Branch behaves as a dimension relative to Order Header and Order Header behaves as a fact relative to Sales Branch.
In this example, all four query subjects are included in a query. The diagram shows that Sales staff and Order details are treated as facts. Order header and Sales branch are treated as dimensions.
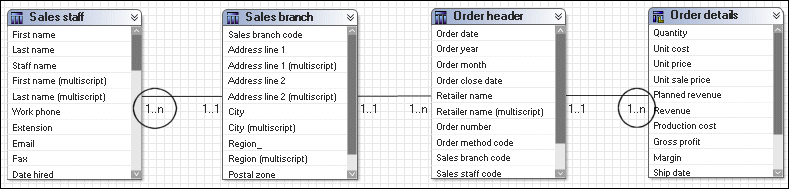
The SQL generated for this query will be split, treating Sales staff and Order details as facts and getting incorrect results. The results of these two subqueries are stitched using the information retrieved from Sales branch. This gives a report that lists the Sales staff information by Sales branch next to the Order details and Order header information by Sales branch. For more information, see Resolving Queries That Are Split in the Wrong Place .
In this example, only three query subjects are included in a query. Order details is not used. Order header is now treated as a fact. Sales staff continues to be treated as a fact.
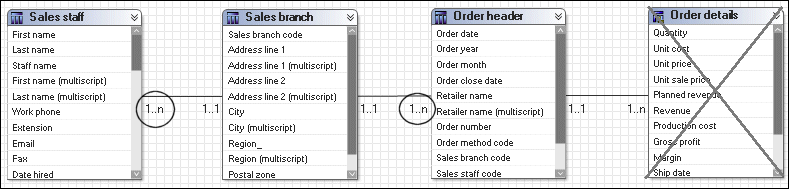
The SQL in this example also generates a stitched query, which returns a similar result as above. Note that a stitch operation retains the information from both sides of the operation by using a full outer join.
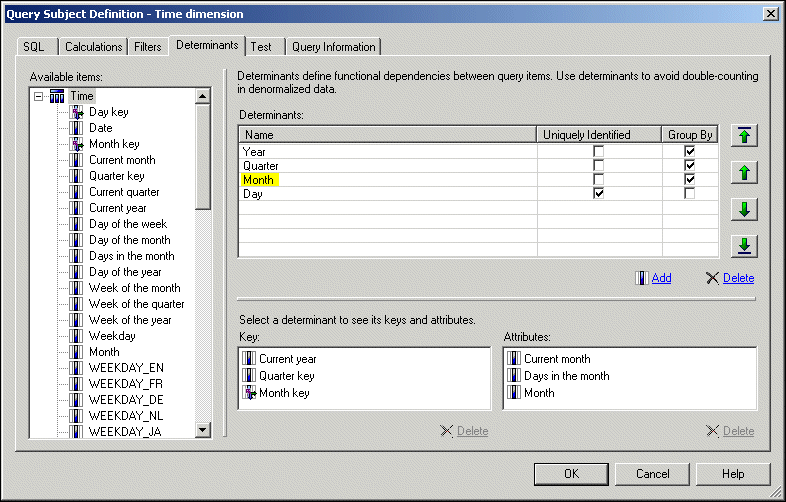
Determinants reflect granularity by representing subsets or groups of data in a query subject and are used to ensure correct aggregation of this repeated data. Determinants are most closely related to the concept of keys and indexes in the data source and are imported based on unique key and index information in the data source. We recommend that you always review the determinants that are imported and, if necessary, modify them or create additional ones. By modifying determinants, you can override the index and key information in your data source, replacing it with information that is better aligned with your reporting and analysis needs. By adding determinants, you can represent groups of repeated data that are relevant for your application.
An example of a unique determinant is Day in the Time example below. An example of a non-unique determinant is Month; the key in Month is repeated for the number of days in a particular month. When you define a non-unique determinant, you should specify group by. This indicates to Cognos 8 that when the keys or attributes associated with that determinant are repeated in the data, it should apply aggregate functions and grouping to avoid double-counting. It is not recommended that you specify determinants that have both uniquely identified and group by selected or have neither selected.
| Year Key | Month Key | Month Name | Day Key | Day Name |
| 2006 | 200601 | January 06 | 20060101 | Sunday, January 1, 2006 |
| 2006 | 200601 | January 06 | 20060102 | Monday, January 2, 2006 |
You can define three determinants for this data set as follows -- two group by determinants (Year and Month) and one unique determinant (Day). The concept is similar but not identical to the concept of levels and hierarchies.
| Name of the Determinant | Key | Attributes | Uniquely Identified | Group By |
| Year | Year Key | None | No | Yes |
| Month | Month Key | Month Name | No | Yes |
| Day | Day Key | Day Name Month Key Month Name Year Key | Yes | No |
In this case, we use only one key for each determinant because each key contains enough information to identify a group within the data. Often Month is a challenge if the key does not contain enough information to clarify which year the month belongs to. In this case, however, the Month key includes the Year key and so, by itself, is enough to identify months as a sub-grouping of years.
Note: While you can create a determinant that groups months without the context of years, this is a less common choice for reporting because all data for February of any year would be grouped together instead of all data for February 2006 being grouped together.
In the Time dimension example above, one key was sufficient to identify each set of data for a determinant but that is not always the case.
For example, the following Geography dimension uses a combination of unique and group by foreign keys. This multiple-part key defines a set in the data.
| Region | Country Key | State/Province Key | City Key |
| North America | USA | Illinois | Springfield |
| North America | USA | Missouri | Springfield |
| North America | USA | California | Dublin |
| Europe | Ireland | n/a | Dublin |
Similar to the example about Time, you can define three determinants for this data set as follows -- two group by determinants (Country and State/Province) and one unique determinant (City). The difference is how you define the key for the City determinant to make it unique.
| Name of the Determinant | Key | Attributes | Uniquely Identified | Group By |
| Country | Country Key | None | No | Yes |
| State/Province | State/Province Key | None | No | Yes |
| City | Country Key State/Province Key City Key | None | Yes | No |
In this case, we used both Country Key and State/Province Key to ensure uniqueness for City. We did this because in the data we were given, some city names were repeated across countries that did not have data for the State/Province Key.
There is no concept of a hierarchy in determinants, but there is an order of evaluation. When Cognos 8 looks at a selection of items from a query subject, it compares them to each determinant (keys and attributes) one at a time in the order that is set in the Determinants tab. In this way, Cognos 8 selects the determinant that is the best match.
In the following example, the attributes current month, days in month, and localized month names are associated to the Month key. When a query is submitted that references any one of these attributes, the Month determinant is the first determinant on which the matching criteria is satisfied. If no other attributes are required, the evaluation of determinants stops at Month and this determinant is used for the group and for clauses in the SQL.
In cases where other attributes of the dimension are also included, if those attributes have not been matched to a previous determinant, Cognos 8 continues evaluating until it finds a match or reaches the last determinant. It is for this reason that a unique determinant has all query items associated to it. If no other match is found, the unique key of the entire data set is used to determine how the data is grouped.
While determinants can be used to solve a variety of problems related to data granularity, you should always use them in the following primary cases:
A query subject that behaves as a dimension has multiple levels of granularity and will be joined on different sets of keys to fact data.
For example, Time has multiple levels, and it is joined to Inventory on the Month Key and to Sales on the Day Key. For more information, see Multiple-fact, Multiple-grain Queries.
There is a need to count or perform other aggregate functions on a key or attribute that is repeated.
For example, Time has a Month Key and an attribute, Days in the month, that is repeated for each day. If you want to use Days in the month in a report, you do not want the sum of Days in the month for each day in the month. Instead, you want the unique value of Days in the month for the chosen Month Key. In SQL, that is XMIN(Days in the month for Month_Key). There is also a Group by clause in the Cognos SQL.
Note that in this section, the term dimension is used in the conceptual sense. A query subject with cardinality of 1:1 or 0:1 behaves as a dimension. For more information, see Cardinality.
Multiple-fact, multiple-grain queries in relational data sources occur when a table containing dimensional data is joined to multiple fact tables on different keys. A dimensional query subject typically has distinct groups, or levels, of attribute data with keys that repeat. The Cognos 8 studios automatically aggregate to the lowest common level of granularity present in the report. The potential for double-counting arises when creating totals on columns that contain repeated data. When the level of granularity of the data is modeled correctly, double-counting can be avoided.
Note: You can report data at a level of granularity below the lowest common level. This causes the data of higher granularity to repeat, but the totals will not be affected if determinants are correctly applied.
This example shows two fact query subjects, Sales and Product forecast, that share two dimensional query subjects, Time and Product.
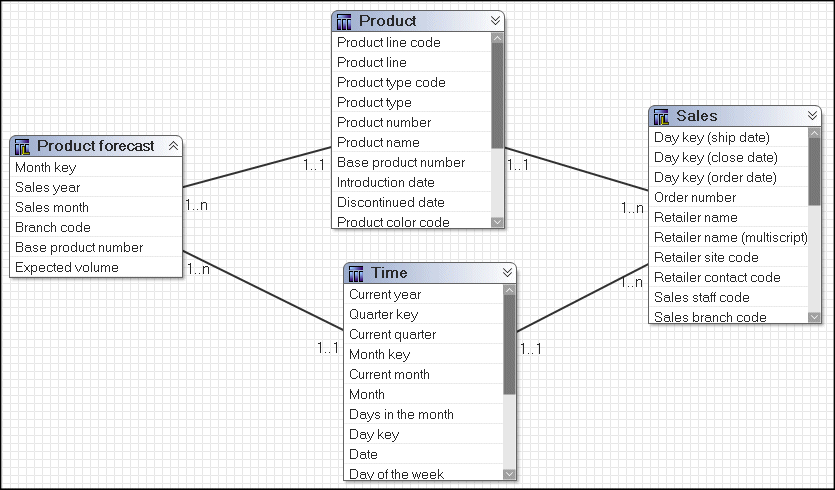
Time is the focal point of the granularity issue in this example. Sales is joined to Time on the Day key, and Product forecast is joined to Time on the Month key. Because of the different join keys, a minimum of two determinants must be clearly identified on Time. For example, the determinants for Month and Day have their keys identified. Day is the unique key for Time, Month keys are repeated for each day in the month.
For example, the determinants for Month are as follows.
The Product query subject could have at least three determinants: Product line, Product type, and Product. It has relationships to both fact tables on the Product key. All joins occur on the Product key so there are no granularity issues.
By default, a report is aggregated to retrieve records from each fact table at the lowest common level of granularity. If you create a report that uses Quantity from Sales, Expected volume from Product forecast, Month from Time, and Product name from Product, the report retrieves records from each fact table at the lowest common level of granularity. In this example, it is at the month and product level.
To prevent double-counting when data exists at multiple levels of granularity, create at least two determinants for the Time query subject. For an example, see Determinants.
| Month | Product name | Quantity | Expected volume |
| April 2007 | Aloe Relief | 1,410 | 1,690 |
| April 2007 | Course Pro Umbrella | 132 | 125 |
| February 2007 | Aloe Relief | 270 | 245 |
| February 2007 | Course Pro Umbrella | 1 | |
| February 2006 | Aloe Relief | 88 | 92 |
If you do not specify the determinants properly in the Time query subject, incorrect aggregation may occur. For example, Expected volume values that exist at the Month level in Product forecast is repeated for each day in the Time query subject. If determinants are not set correctly, the values for Expected volume are multiplied by the number of days in the month.
| Month | Product name | Quantity | Expected volume |
| April 2007 | Aloe Relief | 1,410 | 50,700 |
| April 2007 | Course Pro Umbrella | 132 | 3,750 |
| February 2007 | Aloe Relief | 270 | 7,134 |
| February 2007 | Course Pro Umbrella | 29 | |
| February 2006 | Aloe Relief | 88 | 2,576 |
Note the different numbers in the Expected volume column.
When building a model, it is important to understand that there is no single workflow that will deliver a model suitable for all applications. Before beginning your model, it is important to understand the application requirements for functionality, ease of use, and performance. The design of the data source and application requirements will determine the answer to many of the questions posed in this section.
A frequently asked question is where to create relationships. Should relationships be created between data source query subjects, between model query subjects, or between both? The answer may vary because it depends on the complexity of the data source that you are modeling.
When working with data source query subjects, relationships and determinants belong together.
When working with model query subjects, there are side effects to using relationships and determinants that you should consider:
The model query subject starts to function as a view, which overrides the As View or Minimized setting in the SQL Generation type for a query subject.
This means that the SQL stays the same no matter which items in the query subject are referenced. For more information, see What Is Minimized SQL?.
The model query subject becomes a stand-alone object.
This means underlying relationships are no longer applied, except those between the objects that are referenced. It may be necessary to create additional relationships that were previously inferred from the metadata of the underlying query subjects.
When a determinant is created on a model query subject, the determinant is ignored unless a relationship is also created.
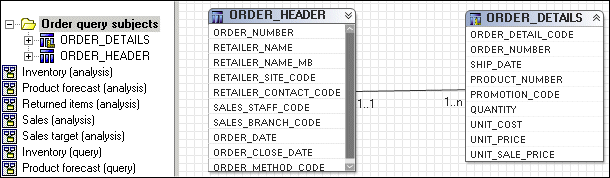
Here is an example of a relationship on a model query subject that purposely overrides the Minimized SQL setting and simplifies the model. In the GO Sales sample model, Order Header and Order Details are combined so that they behave as a single fact. They are placed in their own folder and all relationships to them are deleted except the relationship between Order Header and Order Details. This is the only relationship that will matter after a model query subject is created and relationships attached to it.
To decide where to specify relationships and determinants in the model, you must understand the impact of minimized SQL to your application.
For more information about relationships, determinants, and minimized SQL, see the Model Advisor topics in the Framework Manager User Guide.
When you use minimized SQL, the generated SQL contains only the minimal set of tables and joins needed to obtain values for the selected query items.
To see an example of what minimized SQL means, you can use the Product tables in the GO Sales sample model. Four query subjects, Product Line, Product Type, Product, and Product Multilingual all join to each other.
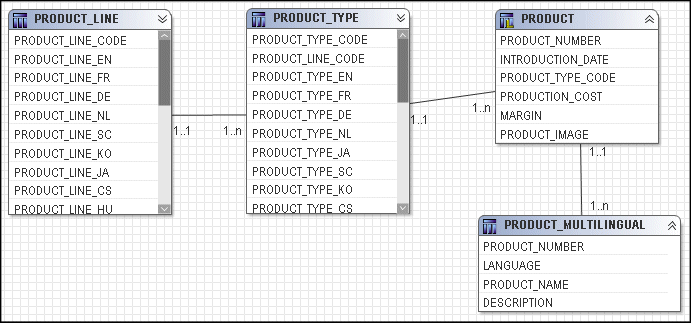
They can be combined in a model query subject.
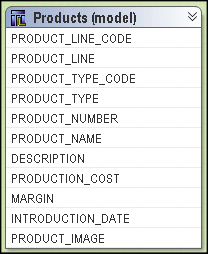
If you test the Products model query subject as a whole, you see that four tables are referenced in the from clause of the query.
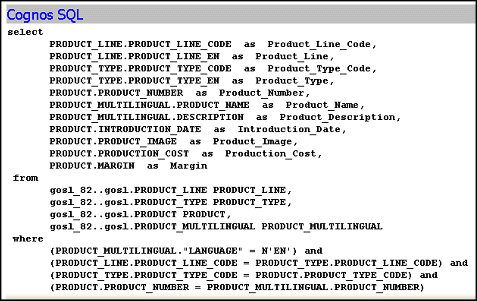
If you test only Product name, you see that the resulting query uses only Product Multilingual, which is the table that was required. This is the effect of minimized SQL.

If you are modeling a normalized data source, you may be more concerned about minimized SQL because it will reduce the number of tables used in some requests and perform better. In this case, it would be best to create relationships and determinants between the data source query subjects and then create model query subjects that do not have relationships.
There is a common misconception that if you do not have relationships between objects, you cannot create star schema groups. This is not the case. Select the model query subjects to include in the group and use the Star Schema Grouping wizard. Or you can create shortcuts and move them to a new namespace. There is no need to have shortcuts to the relationships; this feature is purely visual in the diagram. The effect on query generation and presentation in the studios is the same.
There may be some elements in a data source that you need to encapsulate to ensure that they behave as if they were one data object. An example might be a security table that must always be joined to a fact. If you look at the GO Sales sample model, Order Header and Order Details are a set of tables that together represent a fact and you would always want them to be queried together. For an example, see Where Should You Create Relationships and Determinants?.
Framework Manager stores the metadata that is imported from the data source. However depending on governor settings and certain actions you take in the model, this metadata might not be used when preparing a query. If you enable the Allow enhanced model portability at run time governor, Framework Manager always queries the data source for information about the metadata before preparing a query. If you have not enabled this governor, in most cases Framework Manager accesses the metadata that has been stored in the model instead of querying the data source. The main exceptions are:
The SQL in a data source query subject has been modified. This includes the use of macros.
A calculation or filter has been added to a data source query subject.
Note: The metadata queries generated by Cognos 8 are well supported by most relational database management system vendors and should not have a noticeable impact on most reporting applications.
Query subjects and dimensions serve separate purposes. The query subject is used to generate relational queries and may be created using star schema rules, while the dimension is used for dimensional modeling of relational sources, which introduces OLAP behavior. Because query subjects are the foundation of dimensions, a key success criterion for any dimensional model is a sound relational model.
A dimensional model is required only if you want to use Analysis Studio, to enable drilling up and down in reports, or to access member functions in the studios. For many applications, there is no need for OLAP functionality. For example, your application is primarily for ad hoc query or reporting with no requirement for drilling up and down. Or you are maintaining a Cognos ReportNet model. In these cases, you may choose to publish packages based on query subjects alone.
Determinants for query subjects are not the same as levels and hierarchies for regular dimensions but they can be closely related to a single hierarchy. If you are planning to use your query subjects as the foundation for dimensions, you should consider the structure of the hierarchies you expect to create and ensure that you have created determinants that will support correct results when aggregating. Ensure that you have the following:
The query subject should have a determinant specified for each level of the hierarchy in the regular dimension.
The determinants should be specified in the same order as the levels in the regular dimension.
If you expect to have multiple hierarchies that aggregate differently, you may need to consider creating an additional query subject with different determinants as the source for the other hierarchy.
By creating a complete relational model that delivers correct results and good performance, you will have a strong foundation for developing a dimensional model. In addition, by ensuring that a layer of model objects, either query subjects or dimensions, exists between the data source and the objects exposed to the studios, you are better able to shield your users from change.
The key difference between model objects and shortcuts is that model objects give you the freedom to include or exclude items and to rename them. You may choose to use model objects instead of shortcuts if you need to limit the query items included or to change the names of items.
Shortcuts are less flexible from a presentation perspective than model objects, but they require much less maintenance because they are automatically updated when the target object is updated. If maintenance is a key concern and there is no need to customize the appearance of the query subject, use shortcuts.
Framework Manager has two types of shortcuts:
regular shortcuts, which are a simple reference to the target object.
alias shortcuts, which behave as if they were a copy of the original object with completely independent behavior. Alias shortcuts are available only for query subjects and dimensions.
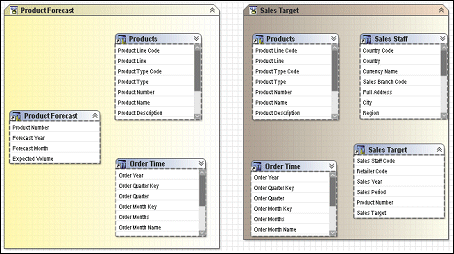
Regular shortcuts are typically used as conformed dimensions with star schema groups, creating multiple references with the exact same name and appearance in multiple places. In the example below, the shortcuts created for Products and Order Time behave as references. If a query is written that brings Products from both Product Forecast and Sales Target, the query uses the definition of Products based on the original and this definition appears only once in the query.
Alias shortcuts are typically used in role-playing dimensions or shared tables. Because there is already an example in this document for role-playing dimensions, we will look at the case of shared tables. In this example, Sales Staff and Sales Branch can be treated as different hierarchies. From our knowledge of the data, we know that because staff can move between branches, we need to be able to report orders against Sales Branch and Sales Staff independently as well as together. To achieve this, we need to create an alias to Sales Branch that can be used as a level in the Sales Staff hierarchy.
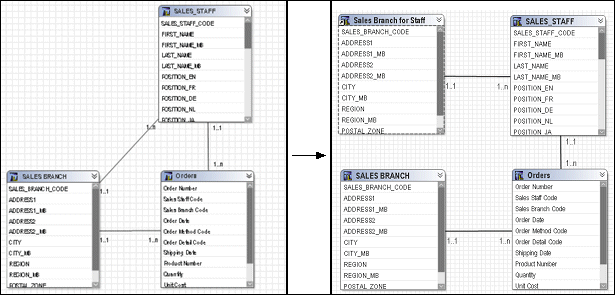
With the new alias shortcut in place, it is possible to create queries that require orders by sales branch and orders by sales staff with their current branch information simultaneously.
Being able to specify the behavior of shortcuts is new to Cognos 8.3.
When you open a model from a previous release, the Shortcut Processing governor is set to Automatic. When Automatic is used, shortcuts work the same as in previous releases, that is, a shortcut that exists in the same folder as its target behaves as an alias, or independent instance, whereas a shortcut existing elsewhere in the model behaves as a reference to the original. To take advantage of the Treat As property, it is recommended that you verify the model and, when repairing, change the governor to Explicit. The repair operation changes all shortcuts to the correct value from the Treat As property based on the rules followed by the Automatic setting, this means that there should be no change in behavior of your model unless you choose to make one or more changes to the Treat As properties of your shortcuts.
When you create a new model, the Shortcut Processing governor is always set to Explicit.
When the governor is set to Explicit, the shortcut behavior is taken from the Treat As property and you have complete control over how shortcuts behave without being concerned about where in the model they are located.
The most important thing to know about namespaces is that once you have begun authoring reports, any changes you make to the names of published namespaces will impact your Cognos 8 content. This is because changing the name of the namespace changes the IDs of the objects published in the metadata. Because the namespace is used as part of the object ID in Cognos 8, each namespace must have a unique name in the model. Each object in a namespace must also have a unique name. Part of the strategy of star schema groups is placing shortcuts into a separate namespace, which automatically creates a unique ID for each object in the namespace. This allows us to use the same name for shortcuts to conformed dimensions in different star schema groups.
The next time you try to run a query, report, or analysis against the updated model, you get an error. If you need to rename the namespace that you have published, use Analyze Publish Impact to determine which reports are impacted.
Folders are much simpler than namespaces. They are purely for organizational purposes and do not impact object IDs or your Cognos 8 content. You can create folders to organize objects by subject or functional area. This makes it easier for you to locate metadata, particularly in large projects.
The main drawback of folders is that they require unique names for all query subjects, dimensions, and shortcuts. Therefore, they are not ideal for containing shared objects such as conformed dimensions.
Regular and measure dimensions are used to enable an OLAP presentation of metadata, drilling up and down, and a variety of OLAP functions. You must use star schema groups (one fact with multiple dimensions) if you want to use Analysis Studio with a relational data source.
When building your model, it is recommended that model regular dimensions and model measure dimensions be created based on a relational model in which star schema concepts have been applied.
While you can convert data source query subjects to data source dimensions, data source dimensions have limited functionality in comparison to query subjects or model dimensions, and they are not recommended for general use.
Regular dimensions represent descriptive data that provides context for data modeled in measure dimensions. A regular dimension is broken into groups of information called levels. In turn, the various levels can be organized into hierarchies. For example, a product dimension can contain the levels Product Line, Product Type, and Product organized in a single hierarchy called Product. Another example is a time dimension that has the levels Year, Quarter, Month, Week, and Day, organized into two hierarchies. The one hierarchy YQMD contains the levels Year, Quarter, Month, and Day, and the other hierarchy YWD contains the levels Year, Week, and Day.
The simplest definition of a level consists of a business key and a caption, each of these referring to one query item. An instance (or row) of a level is defined as a member of that level. It is identified by a member unique name, which contains the values of the business keys of the current and higher levels. For example, [gosales].[Products].[ProductsOrg].[Product]->[All Products].[1].[1].[2] identifies a member that is on the fourth level, Product, of the hierarchy ProductsOrg of the dimension [Products] that is in the namespace [gosales]. The caption for this product is TrailChef Canteen, which is the name shown in the metadata tree and on the report.
The level can be defined as unique if the business key of the
level is sufficient to identify each set of data for a level. In
the GO Sales sample model, the members of the Product level do not
require the definition of Product type because there are no product
numbers assigned to many different product types. A level that is
not defined as unique is similar to a determinant that uses multiple-part
keys because keys from higher levels of granularity are required .
If members within ancestor members are not unique but the level
is defined as unique, data for the non-unique members is reported
as a single member. For example, if City is defined as unique and
identified by name, data for London, England and London, Canada
will be combined.
A regular dimension may also have multiple hierarchies; however, you can use only one hierarchy at a time in a query. For example, you cannot use one hierarchy in the rows of a crosstab report and another hierarchy from the same dimension in the columns. If you need both hierarchies in the same report, you must create two dimensions, one for each hierarchy.
Measure dimensions represent the quantitative data described by regular dimensions. Known by many terms in various OLAP products, a measure dimension is simply the object that contains the fact data. Measure dimensions differ from fact query subjects because they do not include the foreign keys used to join a fact query subject to a dimensional query subject. This is because the measure dimension is not meant to be joined as if it were a relational data object. For query generation purposes, a measure dimension derives its relationship to a regular dimension through the underlying query subjects. Similarly the relationship to other measure dimensions is through regular dimensions that are based on query subjects built to behave as conformed dimensions. To enable multiple-fact, multiple-grain querying, you must have query subjects and determinants created appropriately before you build regular dimensions and measure dimensions.
Scope relationships exist only between measure dimensions and regular dimensions to define the level at which the measures are available for reporting. They are not the same as joins and do not impact the Where clause. There are no conditions or criteria set in a scope relationship to govern how a query is formed, it specifies only if a dimension can be queried with a specified fact. The absence of a scope relationship results in an error at runtime.
If you set the scope relationship for the measure dimension, the same settings apply to all measures in the measure dimension. If data is reported at a different level for the measures in the measure dimension, you can set scope on a measure. You can specify the lowest level that the data can be reported on.
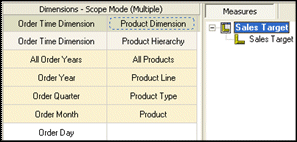
In this example, the Sales Target measure dimension has only one measure that is in scope to the Order Month level on the Order Time Dimension and to the Product level of the Product Dimension. This means that if your users try to drill beyond the month level, they will see repeated data.